{kind=link}

🎯 LLMs are smart, no doubt — but they’re kinda wordy, right?
They love to go step-by-step, super verbose, like:
“Let’s think step by step…”
That’s called Chain of Thought (CoT) prompting. It works, but it’s not exactly efficient.
🔍 But guess what? Humans don’t reason like that.
We don’t narrate every little thing.
We just jot down the important bits — short, snappy, to the point.
💡 Enter: Chain of Draft (CoD) —
A game-changing approach inspired by how we actually think.
Instead of verbose chains, CoD gets LLMs to drop concise, essential thoughts — kind of like mental bullet points.
🧠 And here’s the crazy part:
➡️ It performs just as well — even better than CoT in many cases
➡️ Uses only 7.6% of the tokens 🤯
➡️ Way cheaper and way faster
⚡ So yeah, CoD is like giving your LLM a brain upgrade —
less rambling, more results.
Stay smart. Stay efficient. 🧠✨
Before we proceed further, I’d like to invite you on a deeper exploration into the world of generative AI with my book, “A Generative Journey to AI”. This book is your ultimate guide to mastering the foundations and cutting-edge innovations in generative AI, offering insights and practical strategies to transform your understanding and work in the field. You can grab your copy on Amazon.
Introduction
Reasoning with LLMs has leveled up big time. Models like OpenAI’s o1 and DeepSeek’s R1 are crushing complex tasks — and a big part of that success? Chain of Thought (CoT) prompting. It’s all about getting the model to “think out loud,” breaking down problems step-by-step like a textbook solution. Sounds smart, right? It is. But it’s also super expensive. Verbose outputs, high latency, and bloated token usage — not exactly what you want in a real-world app.
Now pause. Think about how we humans solve problems. We don’t narrate every thought like a podcast. We draft. We scribble key ideas. We write just enough to move forward. That’s the insight behind Chain of Draft (CoD) — a fresh prompting technique that ditches the fluff and gets straight to the point. No overthinking. Just dense, high-signal reasoning steps.
And the results? 🔥 CoD matches CoT in accuracy while slashing token usage by up to 92%. That’s faster responses, lower costs, and leaner models — without compromising performance. We tested CoD on everything from arithmetic to commonsense to symbolic reasoning, and it held its ground — or even outperformed — traditional CoT.
This paper brings three key things to the table:
- A brand-new prompting style — Chain of Draft — inspired by how humans actually think.
- Strong empirical results proving it saves time and tokens without losing smarts.
- A discussion on how CoD could reshape how we design and deploy efficient LLMs.
Progress
In the journey of improving reasoning in large language models, we’ve seen a steady evolution — from simple prompting strategies to structured frameworks designed to mimic how we think. Models like OpenAI o1, DeepSeek R1, and QwQ by Alibaba are part of this shift. They don’t just generate text — they reason, and they do it using deliberate structure.
A foundational step in this space was Chain-of-Thought (CoT) prompting. It encouraged LLMs to think in steps — to explain, reflect, and unravel complexity. Building on this, we saw richer topologies emerge — tree-based reasoning and graph-structured thought flows — allowing models to scale their logic beyond linear paths.
These methods added robustness, but also something else — weight. Token usage increased. Inference latency crept in. The system was thinking better, but slower.
Attempts to ease this burden gave rise to methods like Self-Consistency CoT , which introduced verification, and ReAct, which integrated tools for retrieval. Yet, these came with their own cost — complexity in orchestration and increased inference time.
Other solutions focused purely on speed. Streaming approaches aimed to reduce perceived latency, while Skeleton-of-Thought (SoT) outlined answers first and filled in details later through parallel decoding. Some, like Zhang, explored skipping intermediate layers to generate fast drafts and verify later.
Then came more radical shifts — like Coconut, which moved reasoning into latent space. This improved efficiency, but at a cost: accuracy dropped on harder tasks like GSM8k, and interpretability vanished. Models became fast, but opaque.
Closer to our method are Concise CoT (CCoT) and TALE. CCoT introduces a fixed token budget for reasoning, while TALE estimates the token budget dynamically based on task complexity. The issue? Budgets don’t always align with real-world needs. Tasks vary. And models often exceed those constraints. Worse, TALE needs an extra LLM call just to predict the budget — adding even more latency.
In contrast, Chain of Draft (CoD) introduces a gentler principle: reasoning can be both deep and light. Instead of limiting how far the model can think, CoD limits the verbosity of each step. The model can take as many steps as needed — but every step is minimal, focused, and information-dense. This structure mirrors how we naturally take notes while thinking — not verbose, just enough to move forward.
Chain-of-Draft Prompting
Chain-of-Thought (CoT) prompting has proven to be highly effective, especially on tasks that require multi-step reasoning. By guiding the model to explain its thinking, CoT helps reduce hallucinations and improves transparency. But there’s a cost — verbosity. The reasoning often becomes unnecessarily long, repeating context and inflating token usage, which slows down inference and increases operational cost.

Now contrast this with how humans approach complex tasks. When solving a math problem or navigating a logic puzzle, we don’t explain everything in full sentences. We jot down equations, variables, and key values — just enough to keep the process moving. Our notes are sparse but effective. This natural habit forms the core idea behind Chain-of-Draft (CoD).
Chain-of-Draft is a prompting strategy that encourages concise, information-dense reasoning steps. Instead of elaborating on each phase, the model is guided to express only what’s essential — the calculation or logical transformation that leads to the next step. No filler, no repetition, just meaningful progress.
To see the difference, consider a simple example:
Question: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops did Jason give to Denny?
- Standard Prompting
A direct answer is returned, with no reasoning.
Answer: 8
It’s quick, but we don’t know how the model arrived at this. That’s risky for multi-step tasks.

- Chain-of-Thought Prompting
The model breaks the problem into detailed steps: - Initially, Jason had 20… then gave some to Denny… now has 12… so 20–12 = 8…
This is clear, but verbose. It repeats context (“lollipops”) and uses far more tokens than needed.

- Chain-of-Draft Prompting
The model cuts straight to the core operation:
Answer: 20 — x = 12 → x = 8
It’s minimal, interpretable, and just as accurate — but uses far fewer tokens.

By guiding the model to draft intermediate steps in this compact form, CoD maintains reasoning transparency while being significantly more efficient. This makes it especially useful in production environments where latency and cost are critical.
🧪 How they Tested It — And What they Found
To understand how Chain-of-Draft holds up in practice, we ran a series of tests across three core types of reasoning: arithmetic, commonsense, and symbolic. These categories weren’t chosen randomly — they reflect the kinds of multi-step thinking where most models tend to slow down or over-explain.
We compared three different prompting styles:
- Standard prompting, where models just give the answer.
- Chain-of-Thought, where models think step-by-step — but often in long, wordy explanations.
- Chain-of-Draft, which asks the model to do the same — but with intention: use fewer words, just the essentials.
Two models were tested: GPT-4o and Claude 3.5 Sonnet. Both are high-performing LLMs used widely today.
➗ Can It Do Math, Fast and Right?
The first test was GSM8k — a benchmark filled with school-level math problems that require calculation, logic, and careful steps.
Here’s what we saw:
- Standard prompting produced low accuracy: 53.3% (GPT-4o), 64.6% (Claude).
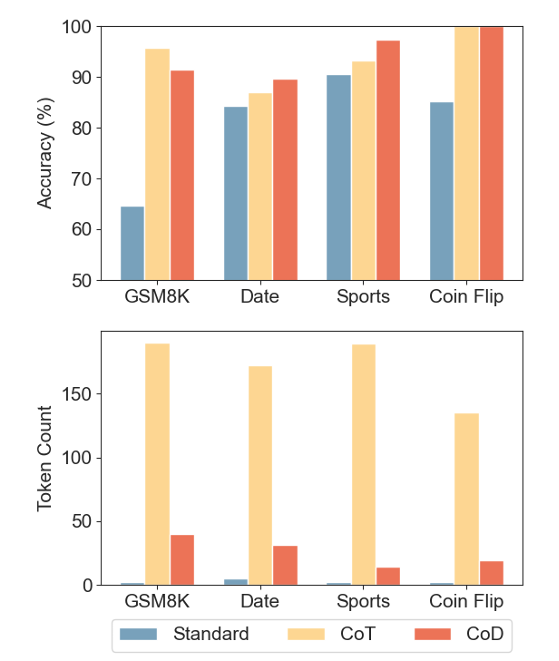
- Chain-of-Thought improved results drastically — but responses were long: ~200 tokens, with a latency of 3–4 seconds.
- Chain-of-Draft hit 91% accuracy using only ~40 tokens, and brought latency down by up to 76%.

This shows that clear thinking doesn’t have to be long thinking.
🧠 Does It Get Everyday Logic?
Next, we turned to commonsense tasks — understanding dates and sports scenarios. These are subtle tasks where clarity matters, but verbosity often creeps in.
Chain-of-Draft didn’t just reduce tokens — it also improved or matched Chain-of-Thought in accuracy. For Claude 3.5 Sonnet, the sports task went from 189 tokens down to 14, with better performance.
It’s not that the model knew less — it simply didn’t waste time saying what wasn’t needed.
🪙 Tracking Change with Minimal Thought
Symbolic reasoning tests how well models follow state — like predicting the result of a sequence of coin flips. We built a new dataset for this, inspired by prior work.
The results were interesting: even without being verbose, models using Chain-of-Draft reached 100% accuracy, just like Chain-of-Thought — but with far fewer tokens.
In both GPT-4o and Claude, token usage was cut by 68–86%, and latency dropped below a second. This matters in systems that need real-time decision-making.
🧭 What This All Means — And Where It Leads
Most research into reasoning with LLMs focuses on accuracy — but latency is just as important. For any real-world system — whether it’s tutoring, support, or assistant tasks — how fast a model responds shapes the user experience.
Chain-of-Draft reminds us of something simple but powerful:
Reasoning doesn’t have to be long to be deep.
By guiding models to write minimally — not skipping steps, but trimming the noise — we make them faster, cheaper, and more focused. And surprisingly, they often become more accurate in the process.
It also opens up new possibilities:
- Can we train models on compact reasoning patterns?
- Can we blend CoD with other optimizations, like parallel decoding or lightweight validation?
- Can we design interfaces that surface these clean drafts to users?
This isn’t just about tokens. It’s about shifting the way we think about thinking — and letting our models do the same.
🔥 Level Up Your SDET Skills 🔥
Monthly Drop : Real-world automation • Advanced interview strategies • Members-only resources